

Barcode 101: Introduction
Barcodes, the ubiquitous sequences of lines or patterns seen on practically every commercial good, are a subtle but tremendously powerful technology that has transformed how businesses function around the world. Barcodes were originally designed to speed up the checkout process in supermarkets, but they have since evolved into a key component of contemporary inventory and supply chain management. Barcodes, which encode information in a format that machines can easily read and decode, have greatly decreased human error, enhanced operational efficiency, and enabled real-time data analysis in a wide range of businesses.
Barcodes are essentially data carriers and can be conveyed in numerous forms. This ultimate guide to barcodes shows the common 1D and 2D barcode languages and how they are applied.
History of Barcodes
The invention of barcodes dates back to 1948, when Bernard Silve overheard a talk at a local grocery shop in Philadelphia about the demand for a method to automatically scan product information during checkout. Intrigued,, Silver collaborated with Norman Joseph Woodland to devise a solution. Woodland created the original barcode design, drawing inspiration from Morse code and dot and dash patterns. This early version had a circular pattern that resembled a bullseye and could be scanned from any direction. Woodland and Silver obtained a patent in 1952 for their innovation, which would become the foundation of modern barcode technology.

The first commercial barcode application occurred two decades later. On June 26, 1974, a pack of Wrigley’s Juicy Fruit gum was the first product sold with a barcode scan at a Marsh supermarket in Troy, Ohio.
This event marked the start of the Universal Product Code (UPC) system, which standardized barcode use throughout the retail industry. The effective use of barcodes at this supermarket revealed barcode technology’s enormous potential and paved the way for its widespread acceptance in sectors worldwide
Understanding Barcodes
Barcodes encode data using changes in parallel lines or, for two-dimensional codes, patterns such as squares or dots. This visual representation of data enables rapid, accurate digital information transfer from physical objects, reducing manual errors and automating inventory and sales procedures. The magic of barcodes is their capacity to ease complex data management, effectively bridging the gap between tangible goods and digital systems.
To scan a barcode, you must first illuminate it with a scanner’s red light, which then reflects back into the device. This reflection alternates between the barcode’s dark bars and light gaps, creating a pattern that a scanner’s photoelectric cell interprets as an electrical, and then digital, signal. This digitized signal is decoded using the barcode’s unique rules or symbology, which converts patterns back to the original encoded data.
Decoding converts scanned signals into usable data by using the symbology’s encoding rules. This process turns the visual information on the barcode into a digital format, similar to a product ID, allowing for instant data access for applications such as pricing and stock management, hence improving operational efficiency across many sectors.
Create Print-Ready Digital .EPS Barcode Files 24/7
A crucial component of precise digital barcode artwork is “bar width adjustment” (BWA), which compensates for gain/reduction occurring in the printing processes. A barcode image file which does not account for BWA will not print accurately for most print technologies. Createbarcode.com is the only GS1 Certified solution to create print-ready digital barcode images.
Types of Barcodes
1D Barcodes
1D linear barcodes are distinguished by a sequence of vertical lines with different widths and spacings. These barcodes are scanned by a laser beam that travels across the linear pattern and encodes data in a horizontal direction.

Common 1D Barcode Languages
UPC (Universal Product Codes)
The UPC-A (also referred to simply as the UPC) is the standard retail “price code” barcode in the United States. UPC-A is strictly numeric; the bars can only represent the digits from 0 to 9. A UPC-A barcode contains 12 digits, along with a quiet (blank) zone on either side, and start, middle, and stop symbols. The middle symbol separates the left side and the right side, which are coded differently.
UPC-A: The numeric 12-digit UPC-A is the most recognized barcode in the world. The encoded data is the GTIN-12 consisting primarily of a Company Prefix and Item Number. Click Here For Additional Information.

UPC-E: Certain manufacturers, whose UPC Company Prefix started with a zero,, have the ability to “zero compress” their data to the 8-digit UPC-E. These prefixes are no longer available.

European Article Number (EAN)
European Article Numbers, or EAN barcodes, are a universal standard for product marking that are frequently used in retail settings. EAN barcodes have 13 digits, while UPCs have 12 digits. This structure is similar to the UPC (Universal Product Code) system, which is mostly used in the United States. Companies who deal internationally will find EANs especially helpful, as this additional number facilitates wider worldwide use.
The compatibility of EAN and UPC barcodes exists despite their variances. Retail operations can run smoothly across geographical boundaries when scanners that can read one can typically read the other. Their mutual ancestry in the same barcode system accounts for their interoperability, which promotes a global strategy for inventory control and product identification.
EAN-13: Local GS1 country offices assign variable length prefixes, and manufacturers assign the remaining product numbers. The total number of numeric digits, including the right check digit is always thirteen.

EAN-8: EAN-8 is a GS1 barcode for use on small items when a full EAN-13 barcode label would be too large to fit. It consists of eight digits. Unlike UPC-E, the EAN-8 is not zero suppressed.
Bookland EAN 13:Unlike the GS1 GTIN model, the global book industry identifies publications with an ISBN (International Standard Book Number). GS1 identified the “country codes” “978” and “979” as the designations for the fictitious country of books (aka Bookland).

Code 39
The Code 39 symbology is alphanumeric and variable-length. It was developed in 1974, and is still in relatively wide use; most barcode readers can read Code 39. In Code 39, each character is made up of five bars and four spaces, with three of those bars/spaces being wide, and the others narrow.
The basic Code 39 system is made up of 43 characters, including capital letters, numbers, and some special/punctuation characters. Depending on the application and the system, it may be possible to use all 128 ASCII characters.

Code 128
Code 128 is a linear barcode that can encode both numbers and letters. The 128-character ASCII set, which consists of many invisible control characters in addition to all the alphabetic, numeric, punctuation, and arithmetic characters on an English-language computer keyboard, is encoded by code 128.
The basic Code 128 barcode format consists of a start code (which sets the initial character set to A, B, or C), the code data, a checksum digit, and a stop code, which marks the end of the barcode. As with other linear barcodes, there are blank quiet zones on either side.

GS1-128 (also known as UCC-128 and EAN-128) is an international standard for using Code 128 in supply-chain barcode labels. GS1-128 consists of the basic Code 128 format with an Application Identifier added to the code data.

GS1 Databar (aka Reduced Space Symbology)
The GS1 Databar family of barcode standards is primarily designed for applications requiring less space. They use an additional leading zero to create a 14-digit format for encoding GTIN-12 (UPC-A) and GTIN-13 (EAN-13) data. Within the Databar family, there are some varieties of linear omnidirectional barcodes. Aside from a single horizontal barcode symbol, there is a stacked version of Databar. To learn about GS1 Databar in detail, please visit. www.databar-barcode.info.
Using GS1 Application Identifiers, GS1 Databar barcodes can encode GTIN item information for point-of-sale systems. They are also used for many other applications.

Omnidirectional and Expanded Databar codes are used in point-of-sale applications, like UPC-A and EAN-13. Expanded codes can include additional information such as weight and expiration date, designated using Application Identifiers in the manner of GS1-128 barcodes.

Interleaved 2 of 5
Interleaved 2 of 5 (or ITF) is a variable-length numbers-only linear barcode. It encodes digits in pairs, with the first digit in each pair represented by bars, and the second digit represented by spaces, so that they are interleaved. Two of the five bars or spaces representing each digit are wide, and the others are narrow.
Interleaved 2 of 5 is included in the GS1 system as the ITF-14 standard, which has a set length of 14 digits.
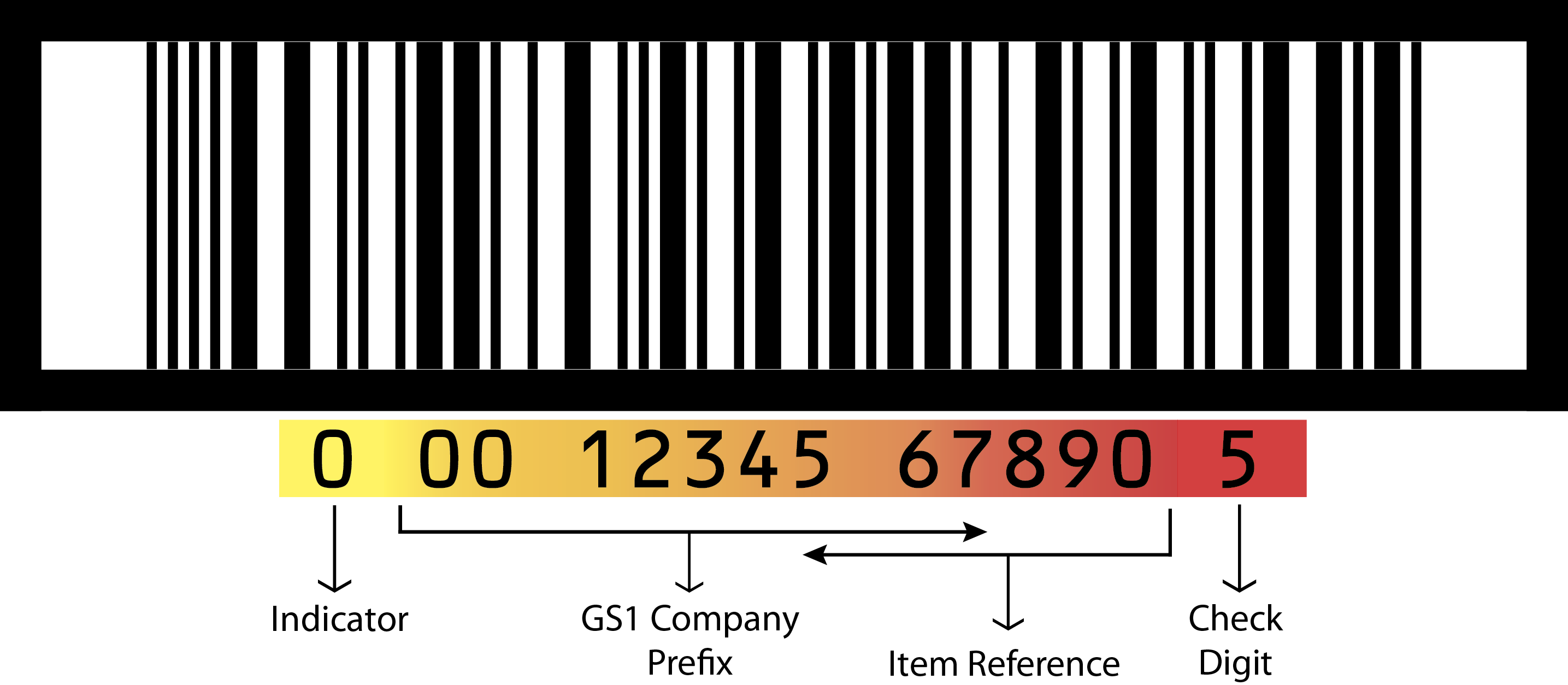
The components of an ITF barcode include the encoded data, a checksum digit (obligatory for ITF-14), a start code (two narrow bar/narrow space pairs), a stop code (wide bar, narrow space, narrow bar), and silent zones on either side.
Within the coded data, patterns that match the start and stop codes may appear. If the scanner does not read the code completely, this could lead to an inaccurate readout. The ITF-14 standard mandates a thick black border known as the bearer bar in order to stop this.
Codabar
Pitney Bowes created codabar initially in 1972. This variable-length barcode encodes the numbers 0 through 9 as well as a few other symbols, such the dollar and plus signs, in certain applications. It is made up of a tiny collection of bars. It also has four start/stop symbols, which are typically represented by the letters A, B, C, and D. Three symbols make up a Codabar code: the coded data, the stop symbol, and the start symbol. Although some apps do provide a check digit, it is self-checking.
Libraries, blood banks, and some businesses, like Federal Express, have long utilized Codabar for airbills, and some of those uses continue today.

Postnet
The Intelligent Mail System, explained below, is gradually replacing Postnet, the barcode system that the USPS has been using to route mail. Postnet codes depict numerals with bars of varying heights.

The ZIP, ZIP+4, and delivery point codes make up a Postnet barcode. Each number is represented by five bars, two of which are full height and the remaining three half-height. (Barcode for Intelligent Mail)
2D Barcodes
In comparison to their 1D predecessors, 2D barcodes can hold far more data because they can store data both vertically and horizontally. This greatly increases their utility by enabling the encoding of not only product information but also photos, website URLs, and other multimedia content.
One clear benefit of 2D barcodes is their ability to hold large amounts of data in a small amount of space. Their support spans a broader range of applications, ranging from sophisticated inventory monitoring and document security to marketing and customer engagement. They are a flexible instrument in digital information transmission because smartphones can scan them, improving user accessibility.
Common 2D Barcode Languages
QR Codes
Originally intended for use in the Japanese automotive sector, the QR (Quick Response) Code format allows users to track automobiles and parts as they are assembled. Its adaptability has led to its widespread usage in a range of industrial and consumer-focused applications. Since QR Codes can now be read by smartphones, their popularity has skyrocketed. To learn more, click here.
Four main types of data can be encoded using QR codes: binary/bytes, alphanumeric characters, numbers, and Japanese kana/kanji. Website URLs can be encoded with QR codes, which enables smartphone users to scan an encoded URL to go straight to a website.

Data Matrix
Black and white square arrays, or cells, arranged in square or rectangular shapes make up DataMatrix barcodes. A DataMatrix barcode may be able to represent as much as 2,355 alphanumeric characters, depending on the kind of encoding. Each cell represents a bit, indicating a one or a zero.
A DataMatrix code contains two different sorts of borders: it appears to have only the two solid borders on one set of adjacent sides because the border alternates between black and white cells on the other two sides. The alternating-cell, or timer, borders enable the scanner to count the rows and columns, while the solid, or finder, borders enable it to orient the code’s image.

GS1 Digital Link
The GS1 Digital Link format allows a single 2D barcode (QR Code or Data Matrix) to provide point-of-sale functionality and also behave as a consumer-facing web-based URL to enhance a consumer experience. Even though large-scale implementation is not slated for a few years, it is imperative that companies understand the importance of how they assign their GTINs and manage their product information today so they can take advantage of this new initiative. To learn more, visit www.gs1digital.link .

PDF417
The PDF417 is a stacked barcode consisting of rows of short bars and spaces that varies in height and breadth. It might contain three rows or ninety rows. The number of data codewords in each row must be the same, however it may range from 1 to 30.
PDF417 can encode numbers, text, and digital data (measured in bytes) all within the single barcode. The start pattern, the left-hand codeword (which serves as the row’s identification), the data codewords, the right-hand codeword, and the stop pattern make up each row of a PDF417 barcode. In contrast to most 2D barcodes, a laser scanner can decode PDF417.

Aztec Codes
The Aztec 2D barcode code resembles the DataMatrix and QR codes.
The DataMatrix and QR codes are similar to the Aztec 2D barcode code. It is composed of a square of white and black cells, or pixels, with a concentric square locating symbol placed right in the middle. Together with other encoding data, the central region (the area surrounding the square bull’s-eye) holds information about the symbol’s size. This indicates that neither a boundary nor an empty space are necessary. Every sixteenth row and column in the code additionally includes an internal reference grid made up of alternating black and white pixels.
Aztec codes could be used in many of the applications for which QR codes are becoming popular, although in practice, their use is more limited. Aztec codes are, however, fairly common in the transportation industry. They are used on airline electronic boarding passes, and for online and mobile railway tickets in many parts of Europe.

Glossary of Important Terms
- Barcode: A machine-readable representation of data, typically displayed as a series of lines or a matrix of squares, used to encode information about an item.
- Linear (1D) Barcode: A barcode that encodes data along a single dimension, using variations in width and spacing of parallel lines.
- Two-Dimensional (2D) Barcode: A barcode that encodes data in both vertical and horizontal dimensions, allowing for significantly more data storage than 1D barcodes.
- Scanner: A device designed to read the information encoded in a barcode by illuminating it and measuring the reflected light.
- Decode: The process by which the pattern in a barcode is interpreted and converted back into readable information.
- Check Digit: A form of error checking used in barcodes, calculated from the other digits in the code, to ensure the barcode is scanned correctly.
- Quiet Zone: A blank margin around a barcode required for accurate scanning. It provides a clear start and end signal to the scanner.
- Symbology: The standard or encoding scheme used to define how characters are represented in the barcode pattern.
- Module: The smallest unit of measure in the design of a barcode, which can be a bar or space.
- Density: The compactness of the information within a barcode, typically measured in characters per inch.
- Read Rate: The success rate at which barcodes are correctly scanned and interpreted by a reader.
- GS1: An international non-profit organization that develops and maintains standards for barcoding and other electronic communication to improve supply chain management and efficiency. Click here to learn more.
- Error Correction: A feature of some 2D barcodes that allows for the recovery of all or part of the data encoded in the barcode even if it is partially obscured or damaged.
- Contrast: The difference in luminance or colour that makes an object distinguishable from other objects and the background.
- Reflectance: The measure of the amount of light reflected from the surface of a barcode, important for the scanning process.
